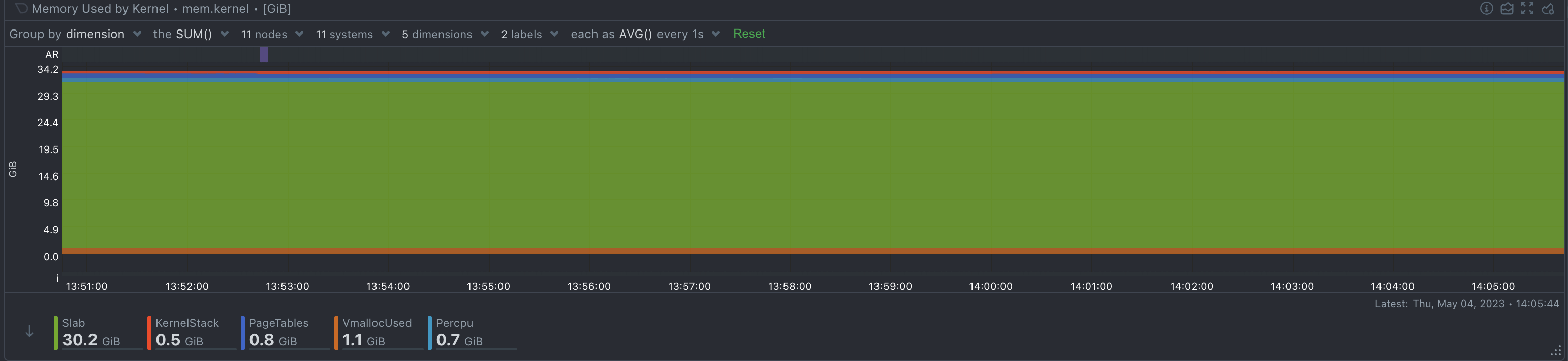
Memory-intensive applications can benefit from improved performance by using huge pages, as they can reduce TLB pressure and memory fragmentation, and lower the memory management overhead overall. Developers should consider using HugeTLBfs in their mmap() and shmget() calls to take advantage of huge pages.
Transparent Huge Pages (THP) is a Linux kernel feature that provides some of the benefits of huge pages without requiring any development effort. However, THP can cause latency in many applications. Although kernel developers are actively working to address these issues, many system administrators prefer to disable THP altogether.
Netdata can assist in determining whether THP is helpful or harmful to your applications, which can guide your decision regarding its use.