
![]()
What is Redis?
Redis is a popular open-source, in-memory data store used across industries by a variety of companies, including Github, Stack Overflow, Twitter and Netdata!
Redis supports multiple use-cases including:
- Real time data store: The versatile in-memory data structures supported by Redis enable building data infrastructure for real-time applications that require low latency and high-throughput.
- Caching & session storage: The high speed data access enabled by Redis makes it ideal for caching database queries, complex computations, API calls, and session state.
- Streaming & messaging: The stream data type enables high-rate data ingestion, messaging, event sourcing, and notifications.
Redis + Netdata
Netdata makes monitoring and troubleshooting Redis simple, effective and powerful.
The prerequisite to this guide is that you have Redis & Netdata installed and running.
Installing Netdata is as easy as it gets; just follow these steps to sign up for a free Netdata account and install the open source agent.
Netdata automatically discovers the Redis service and starts monitoring it, if it is accessible on the localhost on port 6379 (the default port), or via one of the following unix sockets.
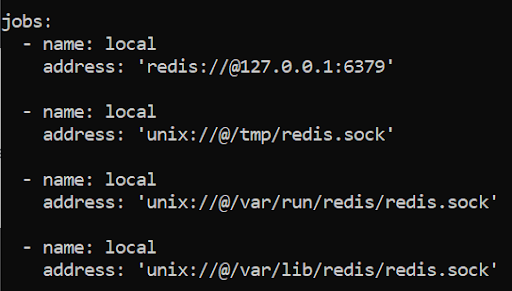
If your Redis service is configured differently or is password protected, you will need to configure the collector.
You should now see a Redis section on the Overview tab that’s already populated with charts about all the metrics you care about!
Redis demo room
Netdata has a public demo space where you can explore different monitoring use-cases.
Check out the Redis demo room to explore and interact with the charts and metrics described in this guide.
Monitoring Redis metrics with Netdata
High fidelity monitoring of Redis enables you to understand the performance of your Redis datastore, whether it is configured optimally or not and also identify any problems that may arise.
This section of the guide explains what metrics are key to understanding Redis and how to make sense of them. All of these metrics are collected by Netdata.
Connections
Redis accepts clients’ connections on the configured listening TCP port and on the Unix socket, if enabled. Redis is capable of handling many active connections, up to a threshold of maxclients, which describes the maximum number of clients that can connect to Redis. The default value is 10,000 client connections. If your system does not have sufficient file descriptors to comply with the maxclients configuration then Redis will use the number of available file descriptors as the limit.
- Accepted connections: Client connection attempts that are accepted per second.
- Rejected connections: Client connection attempts that are rejected due to maxclients limit being exceeded or due to scarcity of available file descriptors.
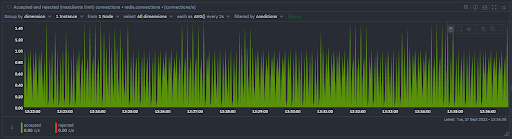
The current state of the clients connected to or attempting to connect to Redis are monitored in a separate chart.
- Connected: Client connected to Redis
- Blocked: Client blocked from connecting to Redis
- In the timeout table: Clients in the timeout table due to be disconnected.
- Tracking: Clients for which client tracking is enabled
Performance
These metrics are the key indicators of Redis performance and overall system health.
Latency
- Latency is the average time it takes from a client request to the server response.
- Monitoring latency allows you to quickly detect variations in Redis performance. Redis is single-threaded and a single long response could cause a cascade effect on subsequent requests.
- High latency could be caused by a number of factors including (but not limited to) slow commands, over utilized network links or a high backlog in the command queue.
- For more information on diagnosing latency issues read the guide from Redis.
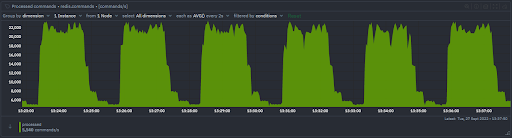
Processed commands per second
- Total number of commands processed per second
- A significant shift in the number (or pattern) of the commands processed is something to watch out for.
- In the example given in the following image, the periodic drops in the number of commands is normal expected behavior - but in abnormal scenarios a drop could be caused by slow commands and enabling the Redis slowlog is a potential way to troubleshoot this.
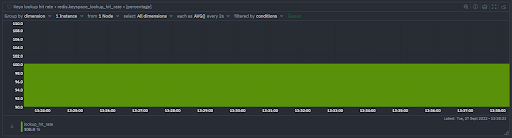
Lookup hitrate
- Lookup hitrate or cache hit ratio is the percentage of successful reads or hits out of all read operations. In other words:
Lookup Hitrate = (Keyspace hits / (Keyspace hits + Keyspace misses))
- This is an important metric to track as lower hitrates result in larger latency due to a greater reliance on disk reads. In normal conditions this value should be greater than 80%
- Note that this metric is meaningful for an application that has been running for some time - for new applications it may be prudent to ignore this number for a while.
- A low lookup hitrate could be caused by a number of factors such as keys getting evicted, keys expiring too soon or keys that simply do not exist.
Memory
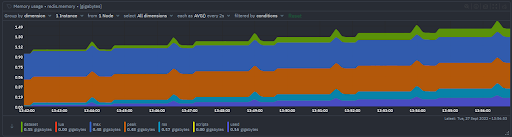
Memory Usage
- Monitoring memory usage is a crucial part of understanding Redis performance
- This chart represents how much memory is consumed by Redis across different components (dataset, lua, max, peak, rss, scripts, used)
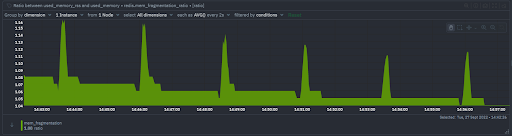
Memory fragmentation
- The ratio of memory allocated by the operating system to memory requested by Redis, or in other words (used_memory_rss/used_memory)
- Ratio > 1.5 indicates excessive fragmentation. (Restarting Redis instance will allow the operating system to recover memory previously unusable due to fragmentation)
- Ratio < 1 indicates Redis needs more memory than is available on your system, which leads to swapping. Swapping to disk will cause significant increases in latency.
- Ratio of equal to 1 or slightly greater is generally considered ideal.
Evicted keys
- This metric is only meaningful to monitor when Redis is used as a cache
- When Redis is used as a cache, it is often convenient to let it automatically evict old data as you add new data.
- To find out more about how the key eviction process and different eviction policies please read the excellent documentation from Redis.
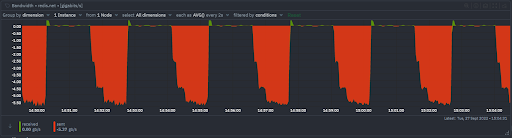
Network
Bytes received and sent
- Bytes received and sent per second by Redis
Replication
Redis supports failover and high availability with asynchronous replication.
Connected replicas
- The number of replicas connected to the primary Redis server
- A sudden drop in the number of connected replicas could indicate a host going down or a problem with the replica instance.
Time since last interaction
- Time in seconds since last interaction between replica and primary
- A long time interval without communication could indicate a problem on the primary Redis server or on the replica or in the link between them.
- When a replica connects (or reconnects) to a master it sends a SYNC command which may cause a latency spike on the primary Redis server.
Time since link down
- Time in seconds since link between replica and primary went down
- This metric is only available when the connection between a primary and its replica has been lost. Any non zero value for this metric is cause for alarm.
Persistence
Redis writes data to disk (durable storage) for persistence. There are multiple persistence options including RDB (Redis database) persistence performance point in time snapshots at specified intervals, AOF (Append only file) persistence logs every write operation received by the server, that will be played again at server startup, reconstructing the original dataset, a mix of the two approaches and also an option to choose no persistence.
If you are using Redis as a cache then persistence may not be necessary. For further information on Redis persistence refer to the official documentation.
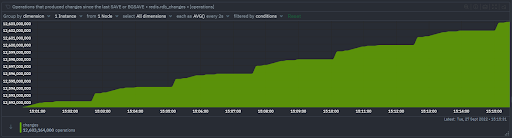
Changes
- Operations that produced changes since the last SAVE or BGSAVE
- This metric gives you an understanding of data volatility, a longer interval to the next SAVE is less consequential if the data is less volatile.
Current BGSAVE time
- Duration of the ongoing RDB save if any (in seconds)
Status of last RDB BGSAVE
- Status of the last RDB BGSAVE, 0 if OK, 1 if error
RDB last SAVE time
- The timestamp of the last RDB SAVE.
AOF file size
- The AOF file size.
Commands
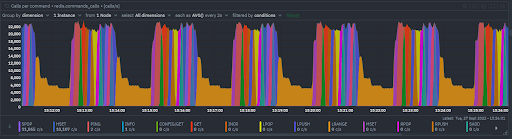
Commands by type
- The total commands per seconds by command type.
- This chart lets you quickly identify the most common commands being processed.
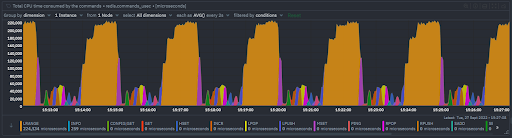
Total CPU time consumed by commands
- The total CPU time consumed by each command type, measured in microseconds.
- This chart lets you quickly identify which command type consumes the most CPU time in total, in the example below it is clear that LRANGE is the outlier in terms of CPU time consumed.
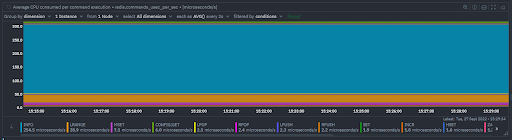
Avg CPU time consumed per command execution
- The average CPU time consumed by each command type, measured in microseconds
- This is distinct from the previous chart since it shows you the variance between the average time per command to total time per all instances of a command being processed.
- The below chart is collected from the same Redis instance as the previous one and while LRANGE was the command that consumed the greatest amount of total time, INFO is the command that consumes the most time in average.
Keyspace
Expired keys
- Measures the number of expired keys per second
- Normally Redis keys are created without an associated TTL (time to live) and the key will live forever unless explicitly removed by the user.
- However the EXPIRE command can be used to associate an expire to a given key which tells Redis to make sure the key is removed after the specified amount of time has elapsed.
Keys per database
- Measures the number of total keys per database
Keys with expiration per database
- Measures the number of keys with an expiration per database. Note that this is distinct from the expired keys metric which measures the keys actually expiring.
Uptime
Uptime
- The duration of time in seconds since the Redis server became operational.
Troubleshooting Redis with Netdata
Alerts
Netdata has a built-in health watchdog that comes with pre configured alerts to reduce the monitoring burden for you.
If you would like to update the alert thresholds for any of these alerts or want to create your own alert for another metric – please follow the instructions here.
By default you will receive email notifications whenever an alert is triggered – if you would not like to receive these notifications you can turn them off from your profile settings.
Anomaly Advisor
Anomaly Advisor lets you quickly identify if the system you are monitoring has any anomalies and allows you to drill down into which metrics are behaving anomalously.
To learn more about how to use Anomaly Advisor to troubleshoot your Redis cluster check out the documentation or visit the demo space.
Metric Correlations
Metric Correlations lets you quickly find metrics and charts related to a particular window of interest that you want to explore further. By displaying the standard Netdata dashboard, filtered to show only charts that are relevant to the window of interest, you can get to the root cause sooner.Hope you are ready and excited to start your Redis monitoring journey with Netdata.
If you haven’t already, sign up now for a free Netdata account!
We’d love to hear from you – if you have any questions, complaints or feedback please reach out to us on Discord or Github.
Happy Troubleshooting!