
We have recently extended the native machine learning (ML) based anomaly detection capabilities of Netdata to support all metrics, regardless on their collection frequency (update every).
Previously only metrics collected every second were supported, but now Netdata can run anomaly detection out of the box with zero config on metrics with any collection frequency.
This post will illustrate an example of what this means using Prometheus metrics (via the Netdata Prometheus collector) since they typically have a default collection frequency of 10 seconds.
Background
The initial implementation of the native ML based unsupervised anomaly detection functionality within Netdata only focused on metrics with update every of 1 second for simplicity.
This was a great starting point and helped keep things simple to reason about in the early days as we dogfooded(fed?) the functionality internally and with the wider Netdata community.
💡 Check out the community launch post from last March for more background.
However not all metrics are captured every second by default and it might be the case that some of your most important metrics get collected by external collectors with less regular update every settings for numerous, perfectly valid, reasons.
This is typically the case with metrics scraped from Prometheus endpoints, often they might be some of the most important metrics (thats how they ended up in a Prometheus endpoint), but they are not collected every second by default. So its crucial the Netdata's anomaly detection "just work" with these metrics too.
Example using Prometheus metrics
As an example of how this now might look, on two of our ml demo nodes we added an example Prometheus scrape job to the Netdata Prometheus collector like below. This just scrapes metrics from the demo prometheus node exporter instance at node.demo.do.prometheus.io
jobs:
- name: node_exporter_demo
url: https://node.demo.do.prometheus.io/metrics
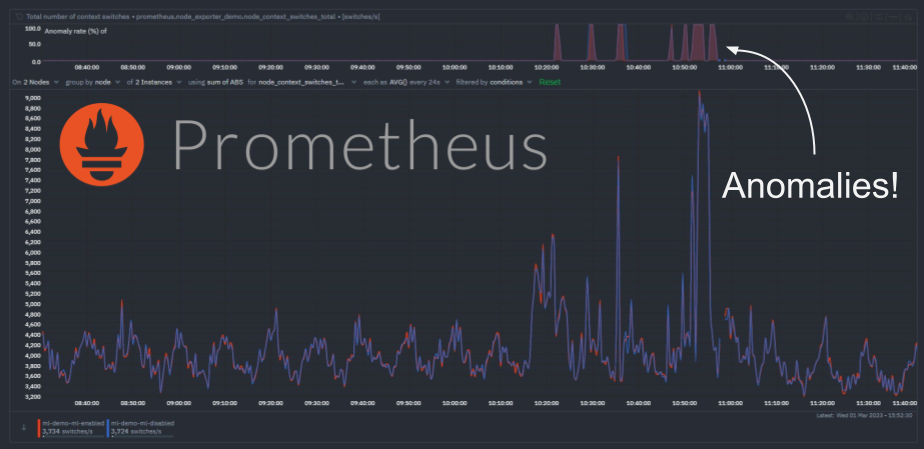
Once sufficient time has passed such that additional ML models can be trained for each new Prometheus metric, we can see the anomaly detection functionality working as expected. Following a period of sudden "spikes" in the node_context_switched_total metric we can see that the corresponding anomaly rate's become more "active".
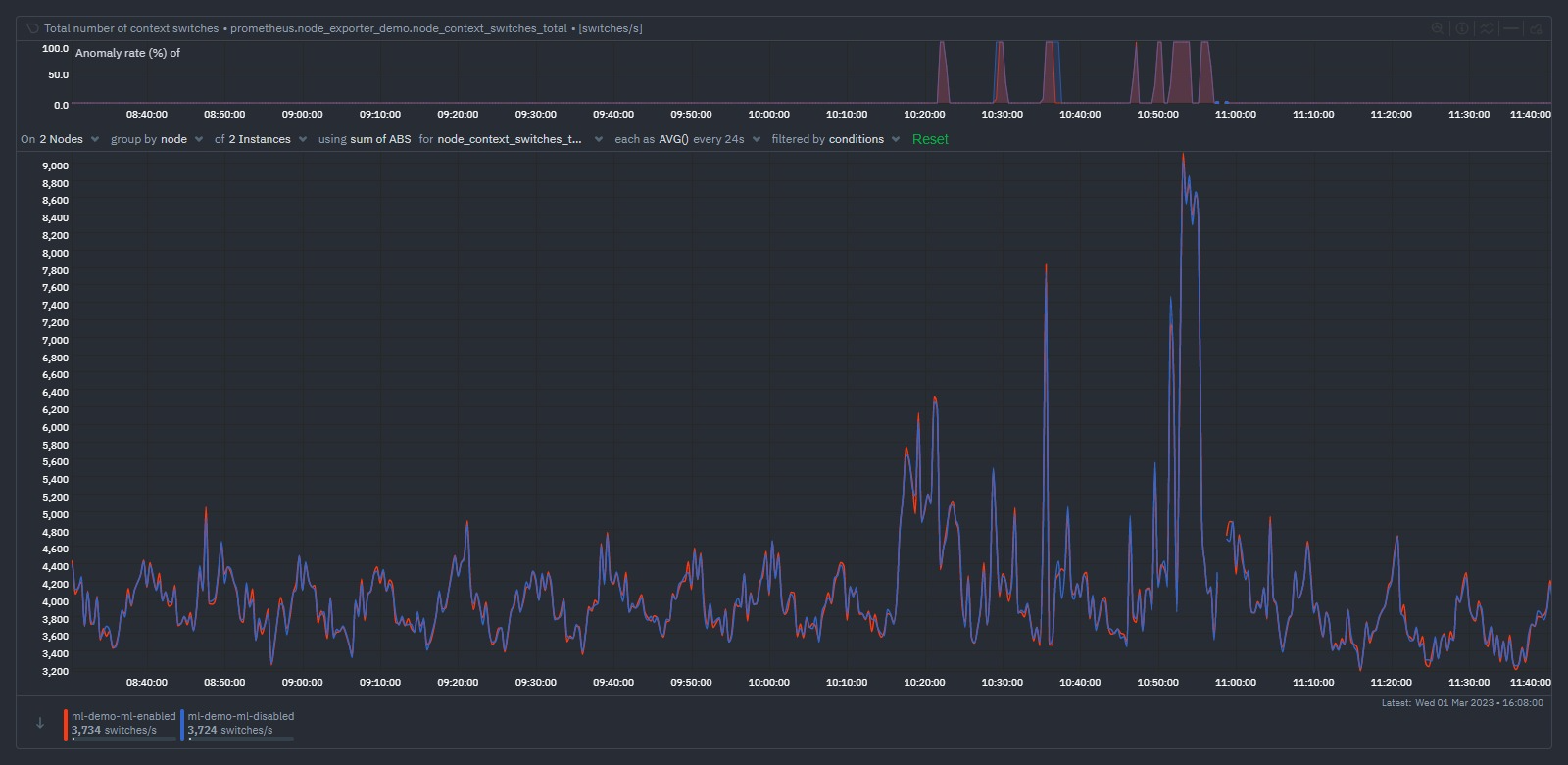
In the example above we have the same prometheus scrape job configured on both nodes just for illustration (one node is running it's own ML ml-demo-ml-enabled while the other is having it's ML done on its parent instead ml-demo-ml-disabled). We see that as the metric becomes a bit more "spikey", the anomaly rate on the top chart activates for each node.
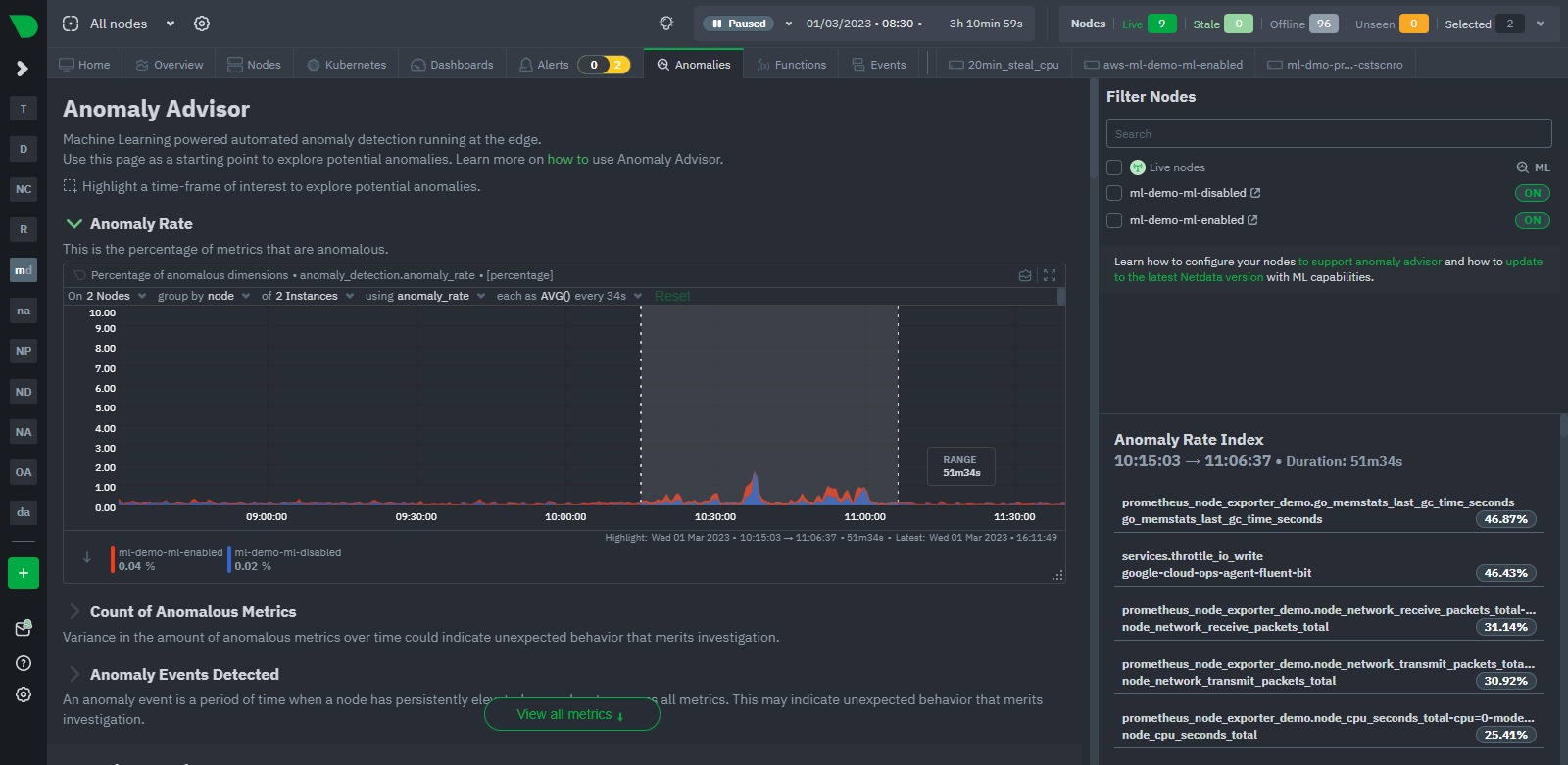
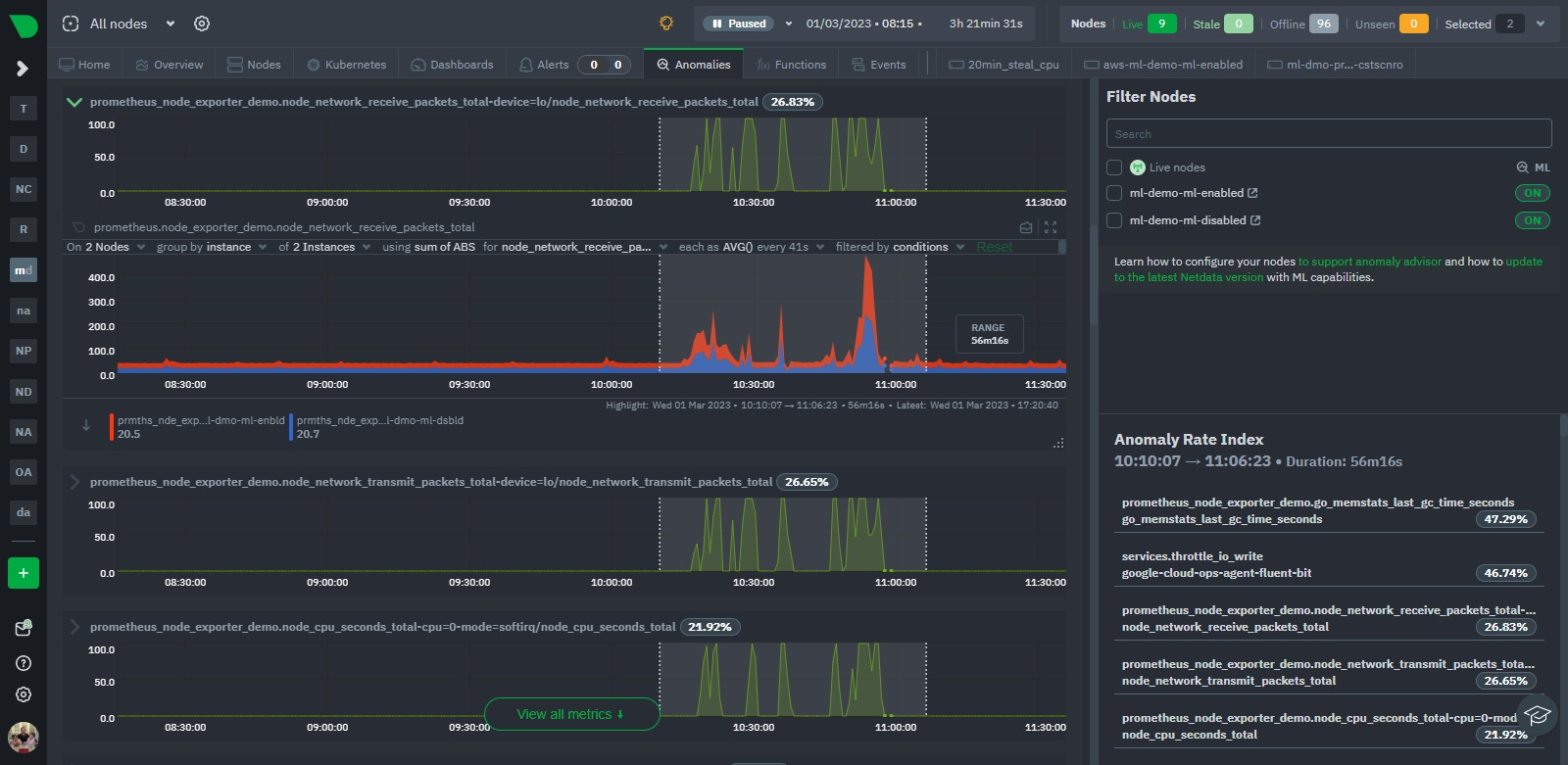
Indeed, if we take a more global look via the Anomaly Advisor tab for the same period we see some bumps in the overall node anomaly rates. Once we highlight the area of interest we can see its mostly the Prometheus metrics that were most anomalous during this window even though they just represent a small fraction of the metrics covered by these nodes.
Conclusion
Thats it, just a short post to show how Netdata's native ML based anomaly detection functionality now works with all metrics regardless of their collection frequency. This is a great step forward for Netdata and we are excited to see how the community uses this functionality.
Next up we will be looking to [Feat]: persist trained ML models to db such that the trained models persist across restarts and upgrades. Following that we hope to update ml defaults to extend the default training windows used by the anomaly detection functionality to roughly 24 hours out of the box.
Feedback!
A lot of the ML based features in Netdata are new and evolving so we would love any and all feedback from the community.
If you have ideas or requests for other features that you'd like to see on Netdata, you can create a GitHub Discussion, open a Feature request on our Netdata Cloud repository or engage with the community on the Netdata Discord, community forums or just drop a comment on in the giscus below this post!